




People used to bookmark tweets using the like feature on Twitter. Later, they introduced Bookmarks feature that helps you save the tweets privately. And now, you have saved thousands of tweets and you can't afford to clear them.
How about we export those bookmarks safely in a file. You can use it as you like - in a web application maybe. It should be noted that Twitter DOES NOT provide an API to access the bookmarks. So, we might have to do some stuff manually here.
I am going to show you how to extract links to the bookmark as well in few lines of python code.
Step 1
Store the Twitter payload in JSON file
An alternative of this step is using the Postman Client. You might want to try it out first, here is the link to a blogpost that allows you to send the request and it's download feature enables you to download the response in a click.
If you don't have the setup, we can get back to copy pasting the response from our good old browser DevTools.
- Open Twitter web and go to the Bookmarks page
- Open Dev tools and go to Network tab
- Clear the network logs and select XHR
- Apply filter as "bookmark"
- Refresh the twitter bookmarks page
You would see some API calls are made as bookmark.json like below image. The API call is subject to change.
Update: Currently, /Bookmarks is used. Twitter has recently started using GraphQL to fetch bookmarks.
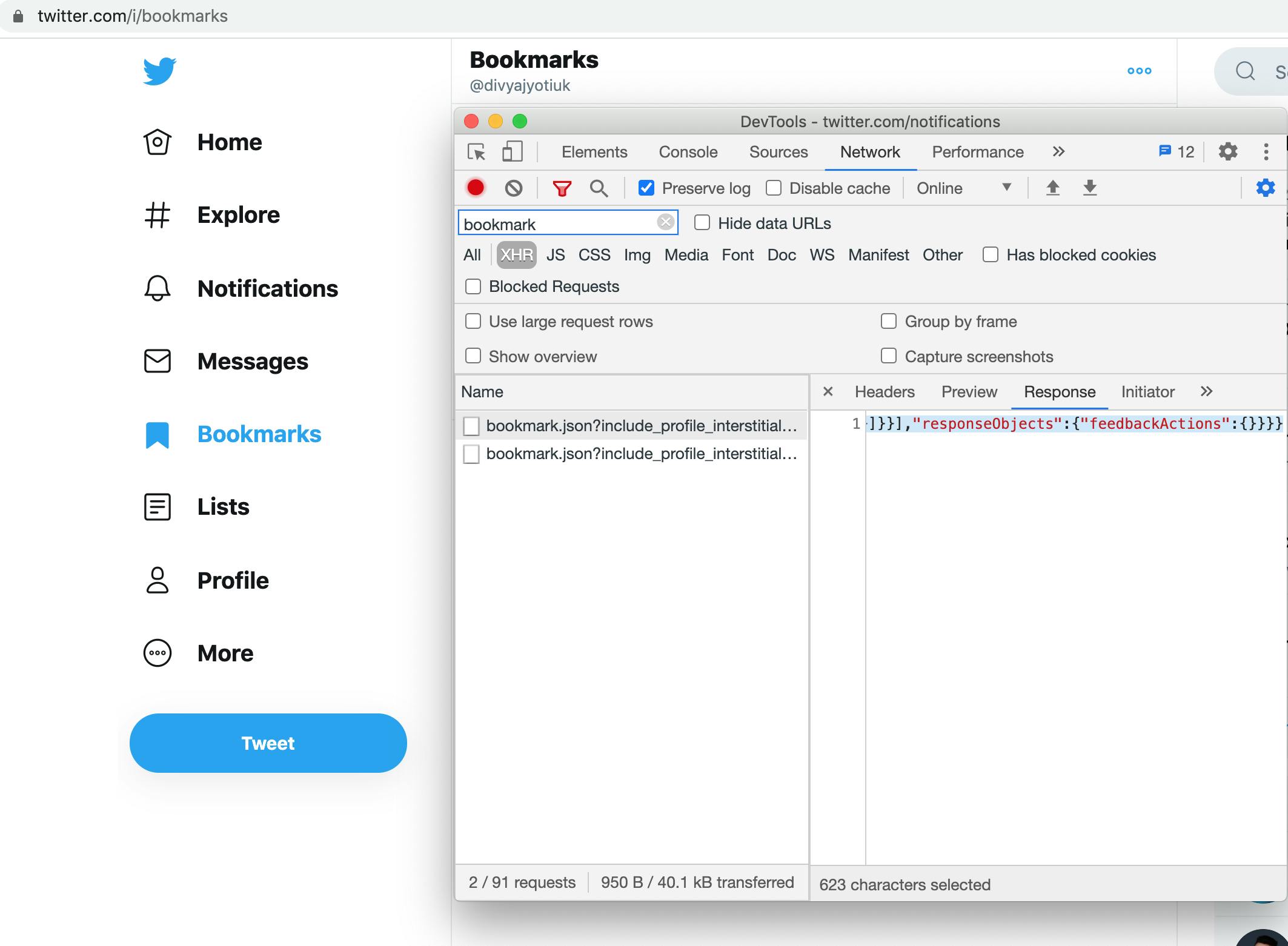
If you have tons of bookmarks, you might have to scroll till the end to get all pagination requests.
- After reaching the end. Select each request and copy paste the response received from the Response tab as shown in the image above.
- Save each response object with .json extension.
Step 2
Getting text and link of bookmarked tweets
- Once you have saved the JSON files, put them in a folder.
Now we just have to write a python script that would get us the links to the Bookmarks and text of the tweet!
- Reading JSON files from folder
import json
import glob
# using glob to read all files in the folder
files = [file for file in glob.glob("JSONBookmarks/*")]
for file_name in files:
print(file_name)
with open(file_name) as bk:
data = json.load(bk) # reads json data
all_bookmarks.append(data)
Here, JSONBookmarks is the folder name. glob() takes the path of the folder to read files from. /* means all files.
The twitter payload explicitly doesn't have the link to the bookmarked tweets.
It provides two primary objects of our use with keys:
- tweets
- users
We will have to use this data in the payload to construct the url to the tweet.
# Function to construct bookmarked tweet url
def constructUrl(tweet_id, username):
return "https://twitter.com/" + username + "/status/" + tweet_id
I have used a deep_get method to get the nested objects.
# Method to get value of nested dictionary
def deep_get(dictionary, keys, default=None):
return functools.reduce(lambda d, key: d.get(key, default) if isinstance(d, dict) else default, keys.split("."), dictionary)
Now the final code that loops through all the tweets to get the data and writes in the markdown.
Update: This logic is subject to change as per Twitter's bookmarks API response!
# saving in markdown file, if no file exists using '+' creates one
# open may take encoding="utf-8" as extra arg for Windows
md_file = open("bookmarks.md", "w+")
# Run a loop through all_bookmarks
for data in all_bookmarks:
instructions_list = deep_get(data, "data.bookmark_timeline.timeline.instructions")
if instructions_list==None: continue
tweet_entries_list = deep_get(instructions_list[0], "entries")
for tweet_entry in tweet_entries_list:
result = deep_get(tweet_entry, "content.itemContent.tweet_results.result")
username = deep_get(result, "core.user_results.result.legacy.screen_name")
text = deep_get(result, "legacy.full_text")
tweet_id = deep_get(result, "rest_id")
if tweet_id == None or username == None or text == None: continue
text = formatText(text)
url = constructUrl(tweet_id, username)
bookmarked_tweet = "\n- " + text + "\n" + "\t - " + url
md_file.write(bookmarked_tweet)
The final output would look like this:
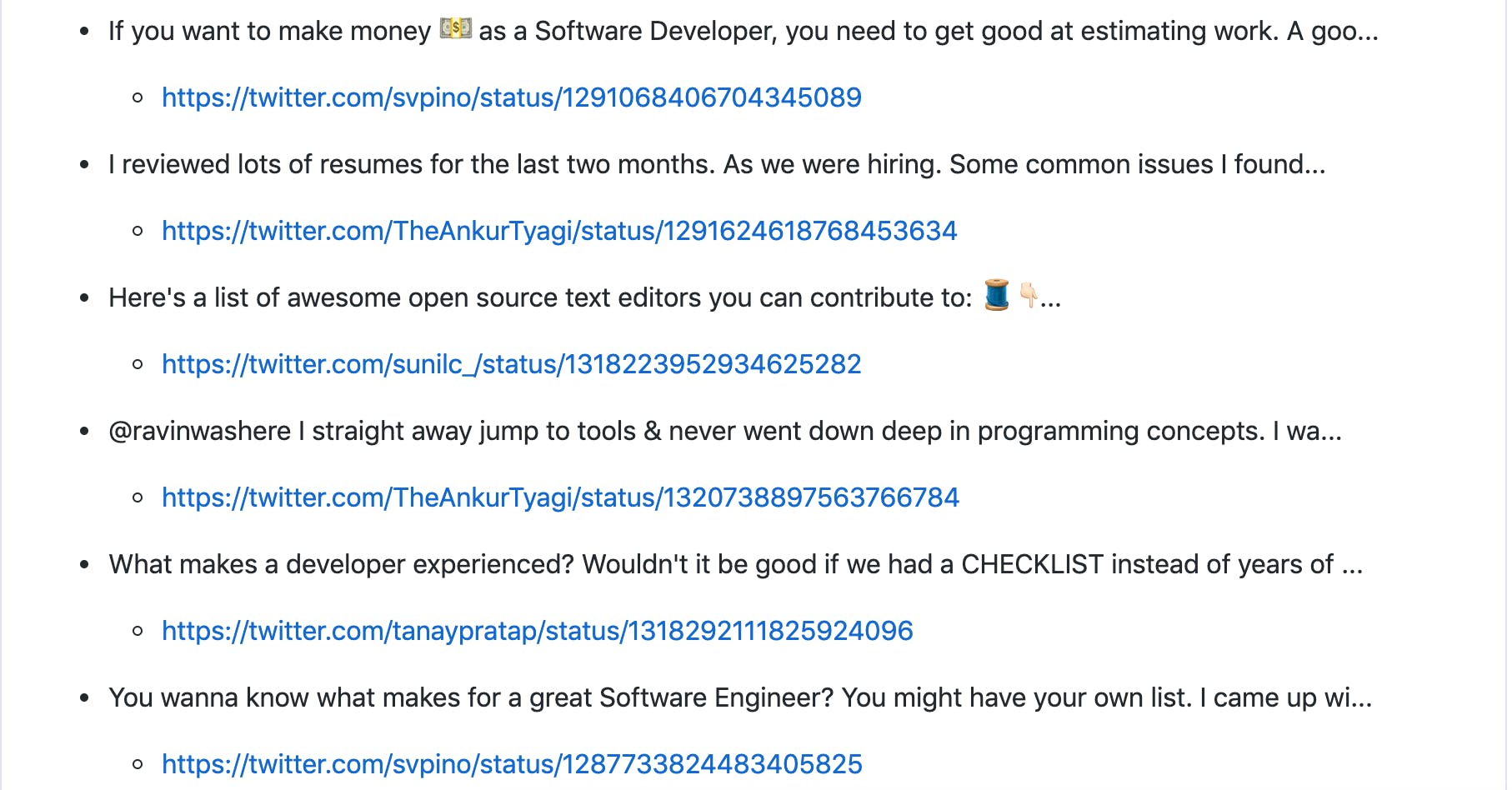
I have formatted it as I wanted, you can do something else too. Here is the whole code for you to refer in this gist. The gist will be updated with new logic if any changes from Twitter API are observed.